The Rise of Autonomous Data Engineering
The era of brittle ETL scripts is ending. For decades, data engineers have been the "plumbers" of the digital world, constantly patching leaky pipelines and debugging obscure SQL errors at 3 AM. But a new paradigm is shifting the landscape: Autonomous Data Engineering.
Beyond "Modern Data Stack"
The so-called "Modern Data Stack" promised simplicity but often delivered fragmentation. We have better tools, but more of them. Maintaining integration between Fivetran, dbt, Airflow, and Snowflake has become a job in itself.
"The future of data engineering isn't better tools to manage complexity, it's removing the complexity entirely through autonomy."
How AI Agents Change the Game
Imagine a data pipeline that doesn't just fail when a schema changes, but adapts. Autonomous agents can:
- Detect Schema Drift: Automatically identify when an upstream API changes its response format.
- Self-Heal: Adjust transformation logic on the fly to accommodate new fields without breaking downstream models.
- Optimize Performance: Continuously tune query performance and cluster sizing without human intervention.
This isn't science fiction. It's the core of what we're building at Zingle. By leveraging LLMs to understand data semantics, we turn "dumb" pipes into intelligent data infrastructure.

The Human in the Loop
Does this mean data engineers are obsolete? Far from it. The role shifts from maintenance to architecture. Instead of writing boilerplate code, engineers define the business logic and governance policies that the agents execute.
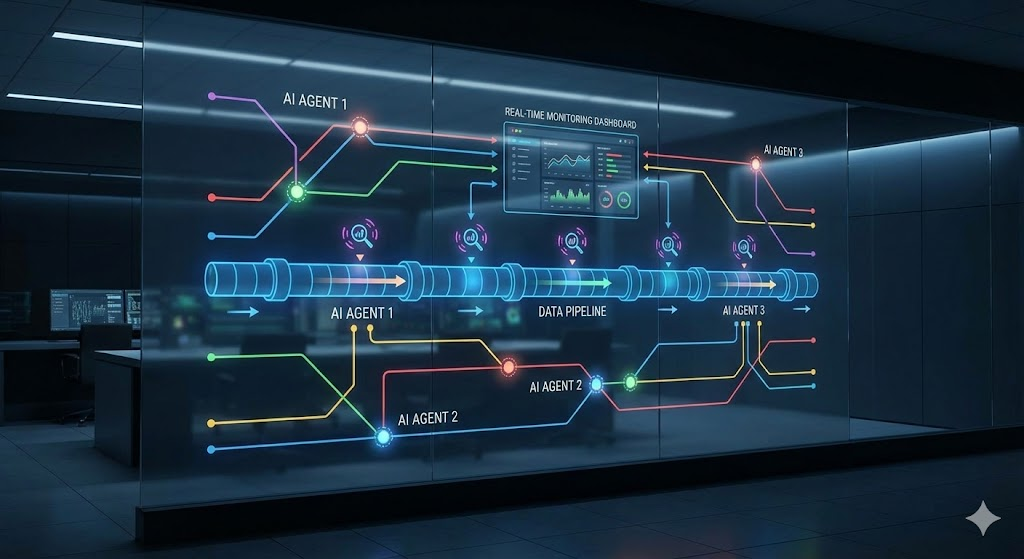
Architecture Visualization
Here is a schematic view of how our AI agents monitor the pipeline in real-time: